for Improved Speech Recognition
Github Repository
A project to use audio super resolution to upsample english speech and feed to speech recognition softwares for better accuracy
The paper for audio super resolution: here :AUDIO SUPER-RESOLUTION USING NEURAL NETS by Volodymyr Kuleshov, S. Zayd Enam, and Stefano Ermon.
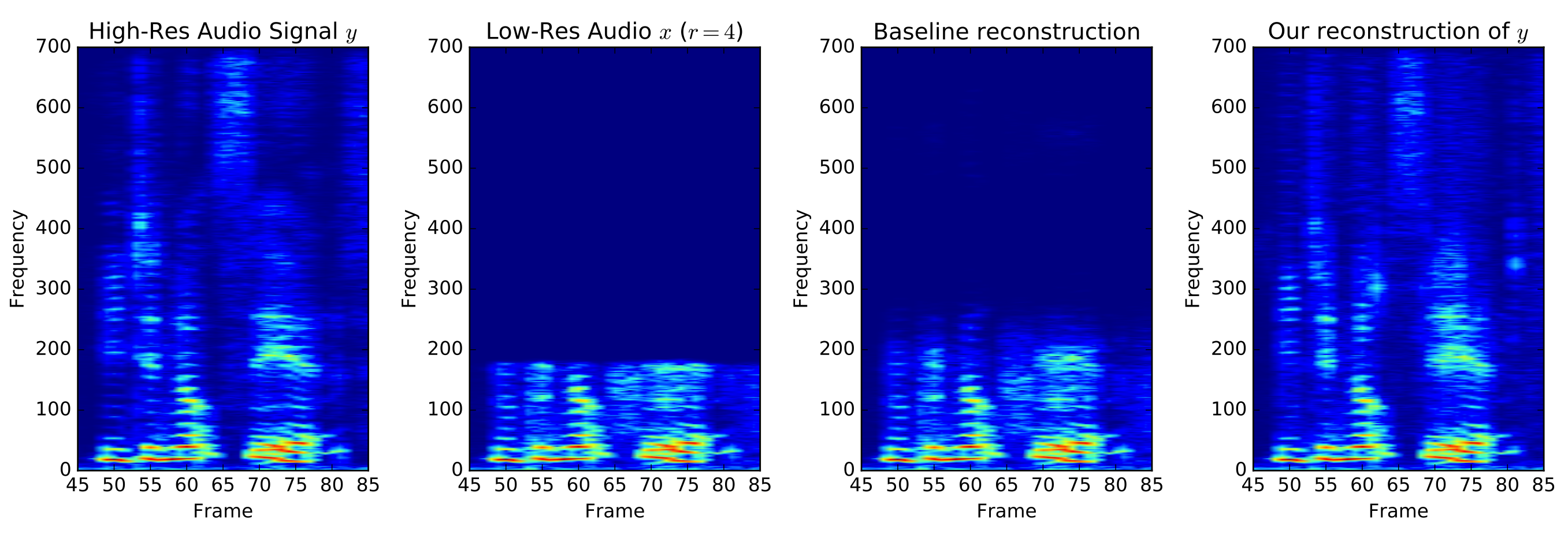
The code has been adapted from the following github repo:here The network has been trained on the VCTK corpus as provided by University of Edinburgh: here